Australia’s Artificial Intelligence Action Plan https://www.industry.gov.au/data-and-publications/australias-artificial-intelligence-action-plan
Bulan: September 2021
Simulasi Pendaratan Starship dari SpaceX
Proses instalasi
conda install pip
pip install jupyter
pip install jupyterthemes
pip install matplotlib
pip install casidiReferensi
- How SpaceX lands Starship (sort of)
- CasADi, build efficient optimal control software with minimal effort
- Original code (Colab): https://colab.research.google.com/drive/18MVtu4reVJLBE1RXByQEmu0O9aLXlMHz
- Cloned code (github): https://github.com/waskita/starship-landing-trajectory/blob/main/starship-trajectory.ipynb
Incorrect Labels in Global Wheat Head Dataset 2021
There are several incorrect labels in Global Wheat Head Dataset 2021. Some images are annotated in their original size. After that, the images are resized to final size (1024×1024 pixels). As the result, the bounding boxes are a little bit off.
Here is the list of affected images
| Image Label | Reason |
| 0af5c1bc753619e4f5d504e5424d056af22954f04d50cd0d4a21682cfdd9a4dc.png | Image file resized after annotation |
| 4c9c82eeefaaa8b3b7300561820274c0ff576b47ada9239862f4a295cbdb18b7.png | Image file resized after annotation |
| 6be51c1a5132034427ecabaafa679fcac7c8f95e05a595df69401766b90d7890.png | Image file resized after annotation |
To correct the annotation, the coordinates must be multiplied by a correction factor and shifted a little bit downward. Here is the comparison between original annotation (green) and corrected annotation (red).



IndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation
Abstract
A benchmark provides an ecosystem to measure the advancement of models with standard datasets and automatic and human evaluation metrics. We introduce IndoNLG, the first such benchmark for the Indonesian language for natural language generation (NLG). It covers six tasks: summarization, question answering, open chitchat, as well as three different language-pairs of machine translation tasks. We provide a vast and clean pre-training corpus of Indonesian, Sundanese, and Javanese datasets called Indo4B-Plus, which is used to train our pre-trained NLG model, IndoBART. We evaluate the effectiveness and efficiency of IndoBART by conducting extensive evaluation on all IndoNLG tasks. Our findings show that IndoBART achieves competitive performance on Indonesian tasks with five times fewer parameters compared to the largest multilingual model in our benchmark, mBART-LARGE (Liu et al., 2020), and an almost 4x and 2.5x faster inference time on the CPU and GPU respectively. We additionally demonstrate the ability of IndoBART to learn Javanese and Sundanese, and it achieves decent performance on machine translation tasks.
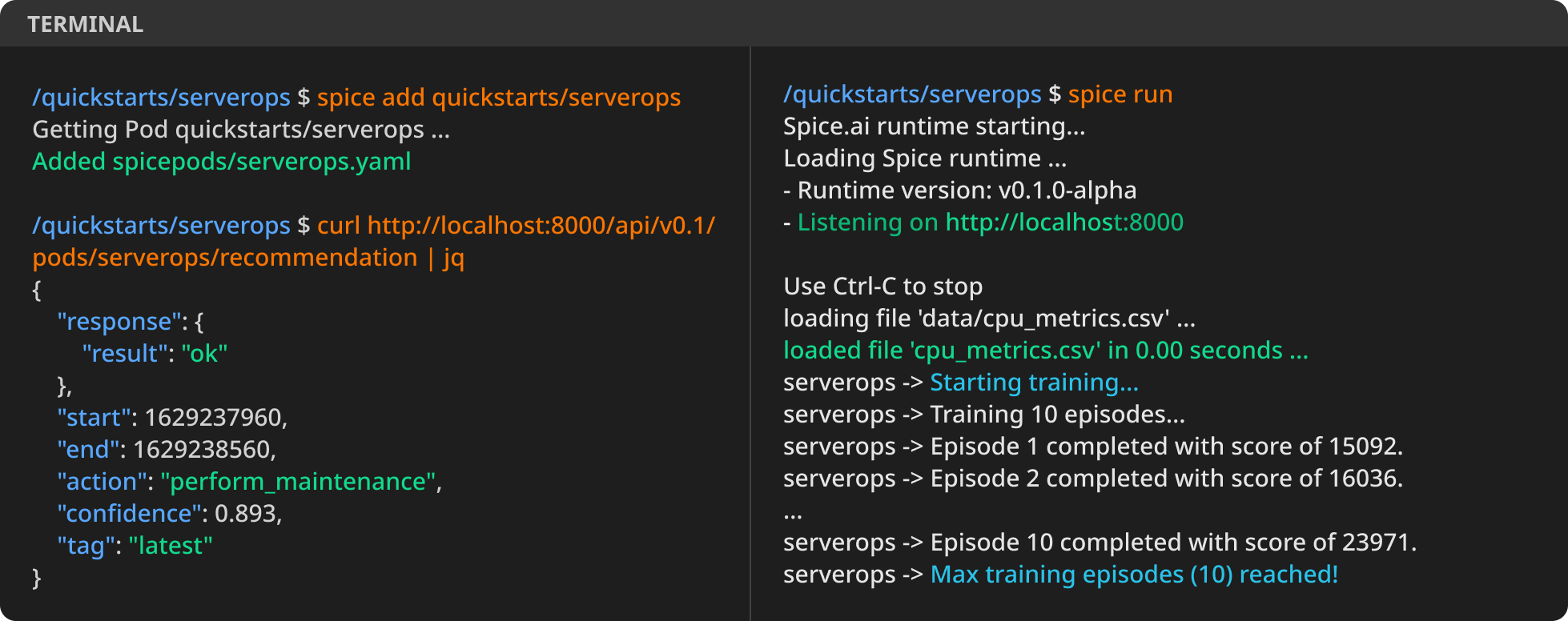
Spice.ai – open source, time series AI
Spice.ai available on GitHub, a new open source project that helps developers use deep learning to create intelligent applications